Abstract
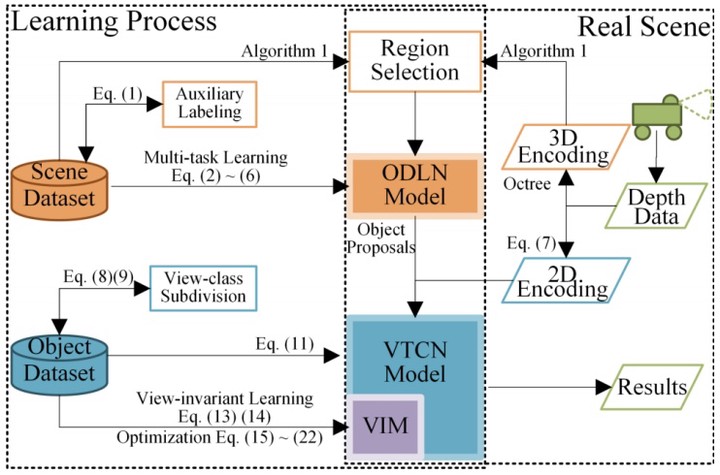
Robotic is a great substitute for human to explore the dangerous areas, and will also be a great help for disaster management. Although the rise of depth sensor technologies gives a huge boost to robotic vision research, traditional approaches cannot be applied to disaster-handling robots directly due to some limitations. In this paper, we focus on the 3D robotic perception, and propose a view-invariant Convolutional Neural Network (CNN) Model for scene understanding in disaster scenarios. The proposed system is highly distributed and parallel, which is of great help to improve the efficiency of network training. In our system, two individual CNNs are used to, respectively, propose objects from input data and classify their categories. We attempt to overcome the difficulties and restrictions caused by disasters using several specially-designed multi-task loss functions. The most significant advantage in our work is that the proposed method can learn a view-invariant feature with no requirement on RGB data, which is essential for harsh, disordered and changeable environments. Additionally, an effective optimization algorithm to accelerate the learning process is also included in our work. Simulations demonstrate that our approach is robust and efficient, and outperforms the state-of-the-art in several related tasks.